Application-Aware Prefetching
Introduction
Application-Aware Prefetching is designed to address the I/O latency of interactive visualization for large-scale volume data. It predicts data access patterns and minimize data movement by bridging view-dependent and data-dependent strategies. The following figure shows the overall process of this tool that has three steps:
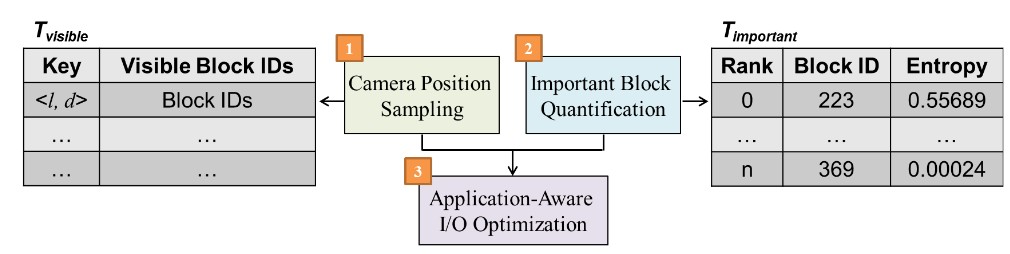
The overview of Application-Aware Prefetching
- The tool samples camera positions according to view directions and distances, and construct a look-up table T_visible to order data blocks according to their view importance.
- The tool quantify the importance of data blocks using an entropy measure, and pre-load the importance blocks to relatively faster memory levels. A table T_importance containing the data importance information of data blocks will be constructed.
- T_visible and T_importance are used to optimized I/O during rendering with possibly dynamically changed transfer functions and view positions. In our I/O optimization, for each position on a camera path, we lookup T_visibleto load the corresponding visible blocks to faster memory for rendering. We also leverageTimportantto pre-load the important blocks to faster memory. Thus, during rendering, only a few blocks will be replaced by LRU policy.
Source code
Click here to download the source code of the prototyping.
Dataset
The tool supports regular volume data. The following datasets are examples:
- Isabel Hurricane simulation data: the description and the download link of the dataset can be found here.
- A combustion simulation dataset made available by Dr. Jacqueline Chen at Sandia National Laboratories: hrr.zip. The dataset contains two files: one head file and one data file. The head file indicates the number of grid points along each axis (x, y, z), and the data type (such as byte, int, float, etc.). The data file contains the 3D or 2D (i.e., z = 1) array of the volume in the C row-major order.
Dependencies
The tool needs to be complied using g++.
Running
To build the executables, run make. It will generate a set of executables in the simulation and optimal folders:
In the simulation folder, there are two executables: track and track_random. The track program simulates view trajectories according to a even distribution of view parameters. The track_random program simulates view trajectories according to a random distribution of view parameters.
In the optimal folders, there are three executables: data_impt, view_impt, and opt_prefetch. The data_impt computes the data importance of a volume data. The view_impt computes the view importance of a volume data. The opt_prefetch program takes the output of data_impt and view_impt, and conducts optimal prefetching according the view trajectories generated by track or track_random. Note that in this prototyping system, the results of the programs are exchanged through files. The three executables correspond to the three steps of the algorithm.
In the simulation folder, there are two executables: track and track_random. The track program simulates view trajectories according to a even distribution of view parameters. The track_random program simulates view trajectories according to a random distribution of view parameters.
In the optimal folders, there are three executables: data_impt, view_impt, and opt_prefetch. The data_impt computes the data importance of a volume data. The view_impt computes the view importance of a volume data. The opt_prefetch program takes the output of data_impt and view_impt, and conducts optimal prefetching according the view trajectories generated by track or track_random. Note that in this prototyping system, the results of the programs are exchanged through files. The three executables correspond to the three steps of the algorithm.
Publication
An Application-Aware Data Replacement Policy for Interactive Large-Scale Scientific Visualization
Lina Yu, Hongfeng Yu, Hong Jiang, Jun Wang.
Proceedings of 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lake Buena Vista, FL, 2017, pp. 1216-1225.
DOI: 10.1109/IPDPSW.2017.16 [PAPER]
DOI: 10.1109/IPDPSW.2017.16 [PAPER]
Citation
@inproceedings{yu2017application,
title={An application-aware data replacement policy for interactive large-scale scientific visualization},
author={Yu, Lina and Yu, Hongfeng and Jiang, Hong and Wang, Jun},
booktitle={2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW)},
pages={1216--1225},
year={2017},
organization={IEEE}
}
Contact