Learning Combinatorial Interaction Test Generation Strategies using Hyperheuristic Search
Overview
The surge of search based software engineering research has been hampered by the need to develop customized search algorithms for different classes of the same problem. For instance, two decades of bespoke Combinatorial Interaction Testing (CIT) algorithm development, our exemplar problem, has left software engineers with a bewildering choice of CIT techniques, each specialized for a particular task. This paper proposes the use of a single hyperheuristic algorithm that learns search strategies across a broad range of problem instances, providing a single generalist approach. We have developed a Hyperheuristic algorithm for CIT, and report experiments that show that our algorithm competes with known best solutions across constrained and unconstrained problems: For all 26 real world subjects, it equals or outperforms the best result previously reported in the literature. We also present evidence that our algorithm’s strong generic performance results from its unsupervised learning. Hyperheuristic search is thus a promising way to relocate CIT design intelligence from human to machine.
Benchmarks
Syn-2: contains 14 different pairwise (2-way) synthetic models without constraints. These models are benchmarksthat have been used both to compare mathematical constructions as well as search based techniques. (download)
| Subjects | Models | Constraints |
|---|---|---|
| S2-1 | 34 | N/A |
| S2-2 | 513822 | N/A |
| S2-3 | 313 | N/A |
| S2-4 | 41339225 | N/A |
| S2-5 | 514431125 | N/A |
| S2-6 | 415317229 | N/A |
| S2-7 | 6151463823 | N/A |
| S2-8 | 716151453823 | N/A |
| S2-9 | 4100 | N/A |
| S2-10 | 616 | N/A |
| S2-11 | 716 | N/A |
| S2-12 | 816 | N/A |
| S2-13 | 817 | N/A |
| S2-14 | 1020 | N/A |
Syn-3: contains 15 different 3-way synthetic models without constraints. These beenchmarks that have been used for mathematical constructions and search. (download)
| Subjects | Models | Constraints |
|---|---|---|
| S3-1 | 36 | N/A |
| S3-2 | 46 | N/A |
| S3-3 | 324252 | N/A |
| S3-4 | 56 | N/A |
| S3-5 | 57 | N/A |
| S3-6 | 66 | N/A |
| S3-7 | 664222 | N/A |
| S3-8 | 101624331 | N/A |
| S3-9 | 88 | N/A |
| S3-10 | 77 | N/A |
| S3-11 | 99 | N/A |
| S3-12 | 106 | N/A |
| S3-13 | 1010 | N/A |
| S3-14 | 1212 | N/A |
| S3-15 | 1414 | N/A |
Syn-C2: contains 30 different 2-way synthetic models with constraints These models were designed to simulate configurations with constraints in real world programs, generated by Cohen et al. and adopted in follow-up research by Garvin et al. (download)
| Subjects | Models | Constraints |
|---|---|---|
| C2-S1 | 28633415562 | 2203341 |
| C2-S2 | 2_{8633435161 | 21933 |
| C2-S3 | 22742 | 2931 |
| C2-S4 | 251344251 | 21532 |
| C2-S5 | 215537435564 | 2323641 |
| C2-S6 | 2734361 | 22634 |
| C2-S7 | 22931 | 21332 |
| C2-S8 | 210932425363 | 2323441 |
| C2-S9 | 25731415161 | 23037 |
| C2-S10 | 213036455264 | 24037 |
| C2-S11 | 28434425264 | 22834 |
| C2-S12 | 213634435163 | 22334 |
| C2-S13 | 212434415262 | 22234 |
| C2-S14 | 281354363 | 21332 |
| C2-S15 | 25034415261 | 22032 |
| C2-S16 | 281334261 | 23034 |
| C2-S17 | 212833425163 | 222534 |
| C2-S18 | 212732425163 | 2233441 |
| C2-S19 | 217239495364 | 23835 |
| C2-S20 | 213834455467 | 24236 |
| C2-S21 | 27633425163 | 24036 |
| C2-S22 | 2733343 | 23134 |
| C2-S23 | 2253161 | 21332 |
| C2-S24 | 2110325364 | 22534 |
| C2-S25 | 211836425266 | 2233341 |
| C2-S26 | 287314354 | 22834 |
| C2-S27 | 25532425162 | 21733 |
| C2-S28 | 2167316425366 | 23136 |
| C2-S29 | 21343753 | 21933 |
| C2-S30 | 272344162 | 22032 |
Real-1: contains real world models from a recent benchmark created by Segall et al. There are 20 CIT problems in this subject set, generated by or for IBM customers. The 20 problems cover a wide range of applications, including telecommunications, healthcare, storage and banking systems. (download)
| Subjects | Models | Constraints |
|---|---|---|
| Concurrency | 25 | 243152 |
| Storage1 | 21314151 | 495 |
| Banking1 | 3441 | 5112 |
| Storage2 | 3461 | - |
| CommProtocol | 21071 | 210310412596 |
| SystemMgmt | 253451 | 21334 |
| Healthcare1 | 26325161 | 23318 |
| Telecom | 2531425161 | 2113149 |
| Banking2 | 21441 | 23 |
| Healthcare2 | 253641 | 2136518 |
| NetworkMgmt | 224153102111 | 220 |
| Storage3 | 2931536181 | 238310 |
| Proc.Comm1 | 233646 | 213 |
| Services | 23345282102 | 338642 |
| Insurance | 26315162111131171311 | - |
| Storage4 | 25374152627191131 | 224 |
| Healthcare3 | 21636455161 | 231 |
| Proc.Comm2 | 233124852 | 142121 |
| Storage5 | 253853628191102111 | 2151 |
| Healthcare4 | 21331246526171 | 222 |
| Subjects | Models | Constraints |
|---|---|---|
| TCAS | 273241102 | 23 |
| Spin-S | 21345 | 213 |
| Spin-V | 24232411 | 24732 |
| GCC | 2189310 | 23733 |
| Apache | 215838445161 | 23314251 |
| Bugzilla | 2493142 | 2431 |
Experiment Settings
All experiments but one are carried out on a desktop computer with a 6 core 3.2GHz Intel CPU and 8GB memory. To understand the trade off between the quality of the results and the cost of the hpyerheuristics approach, we used the Amazon EC2 Cloud. All experiments are repeated five times and we report the best and the average results over these five runs.
Results
This section contains only the research questions and results of tables and figures, a much detailed explanation and discussion of these results can be found in our paper.
RQ1: What is the quality of the test suites generated using the hyperheuristic approach?
One of the primary goals of CIT is to find the smallest test suite (defined by the covering array) that achieves the desired strength coverage. It is trivial to generate an arbitrarily large covering test suite - simply include one test case for each interaction to be covered. However, such a na ̈ıve approach to test generation would yield exponentially many test cases. All CIT approaches therefore work around problem of finding a minimal size covering array for testing. The goal of CIT is to try to find the smallest test suite that achieves 100% t-way interaction coverage for some chosen strength of interaction t.
In following tables, we include the best reported solution from the literature followed by the smallest CIT sample and its running time for each of the three settings of the HHSA.
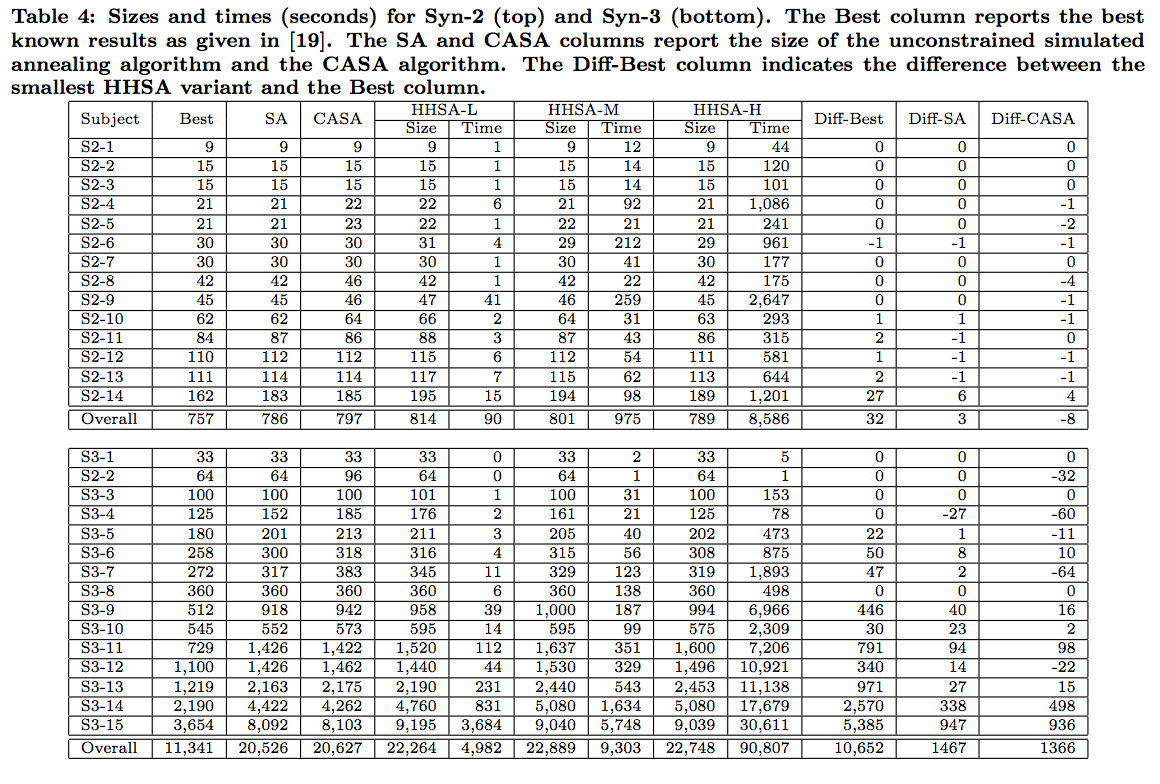
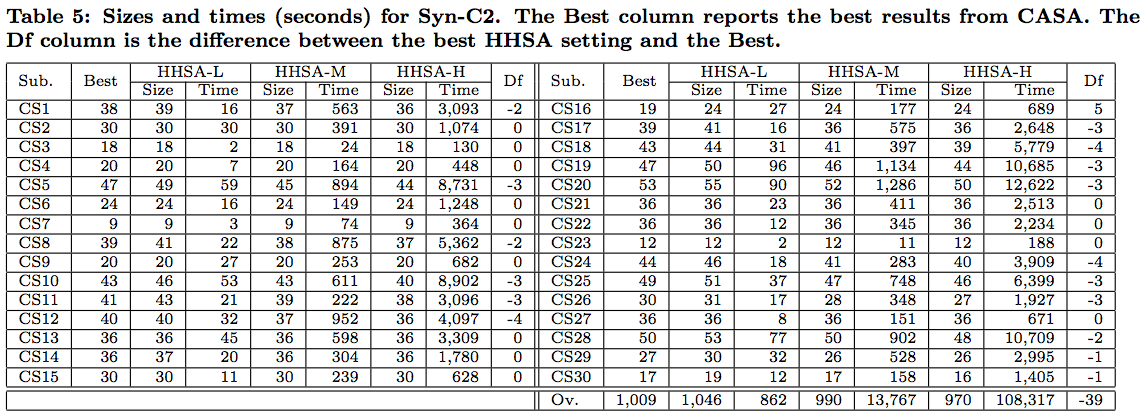
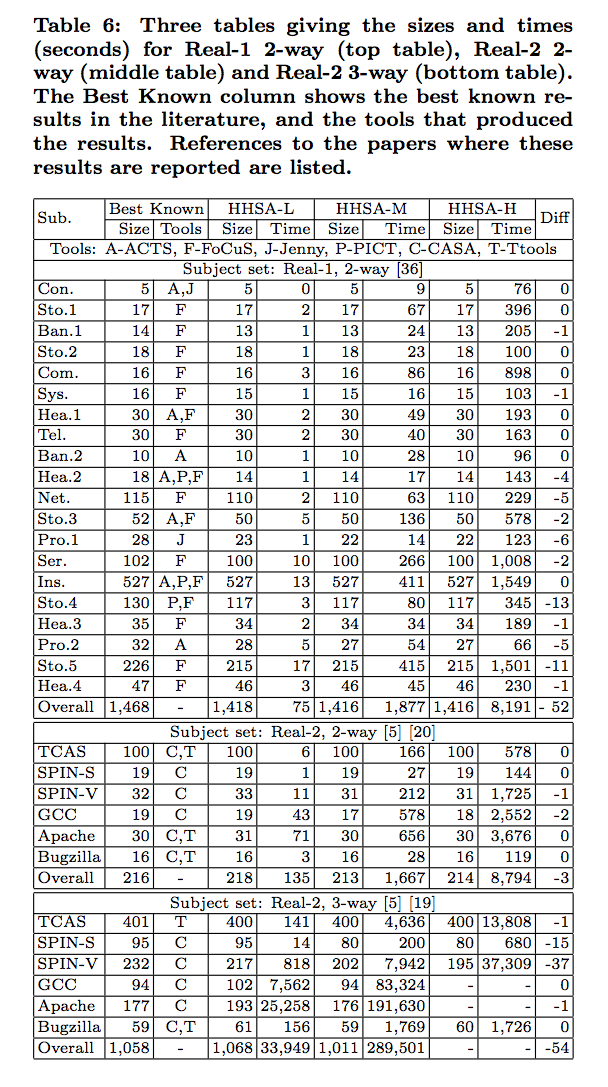
We conclude that the quality of results obtained by using HHSA is high. While we do not produce the best results on every model, we are quite competitive and for all of the real subjects we are as good as, or improve upon the best known results.
RQ2: How efficient is the hyperheuristic approach and what is the trade off between the quality of the results and the running time?
Another important issue in CIT is the time to find a test suite that is as close to the minimal one as possible given time budgeted for the search. Depending on the application, one might want to sacrifice minimality for efficiency (and vice-versa). This research question therefore investigates whether the hyperheuristic approach can generate small test suites in reasonable time.
The following Tables summarize the average execution time in seconds per subject within each group of benchmarks, using the three configurations of HHSA.
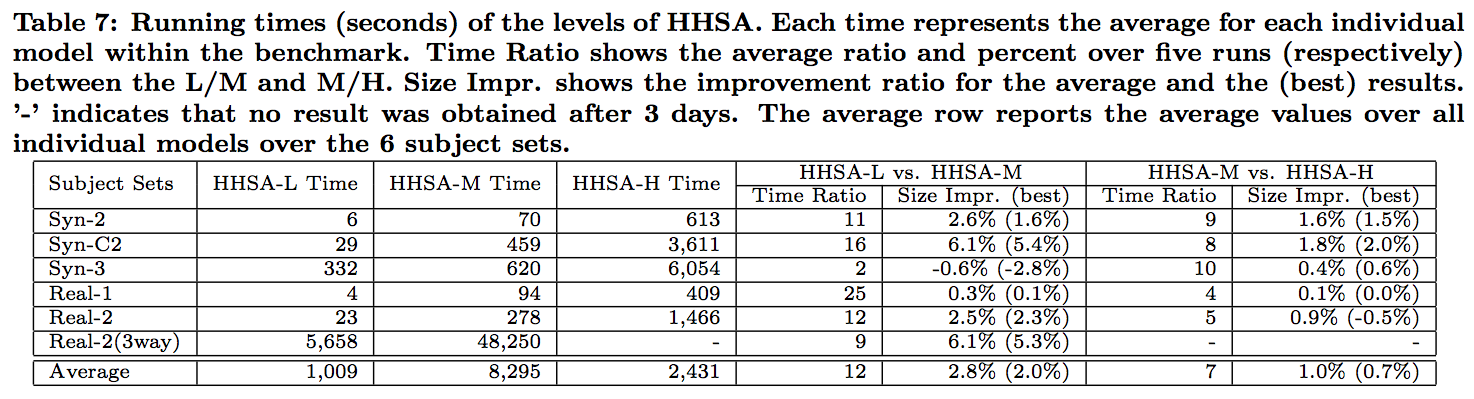

We conclude that the HHSA algorithm is efficient when run at the lowest level (HHSA-low). When run at the higher levels we see a cost-quality tradeoff. In practice, however, the monetary cost of running these algorithms is very small.
RQ3: How efficient and effective is each search navigation operator in isolation ?
In order to collect baseline results for each of the operators that the hyperheuristic approach can choose, we study the effects of each operator in isolation. That is, we ask how well each operator can perform on its own.
Should it turn out that there is a single operator that performs very well, then there would be no need for further study; we could simply use the high performing operator in isolation. Similarly, should one operator prove to perform poorly and to be expensive then we might consider removing it from further study.
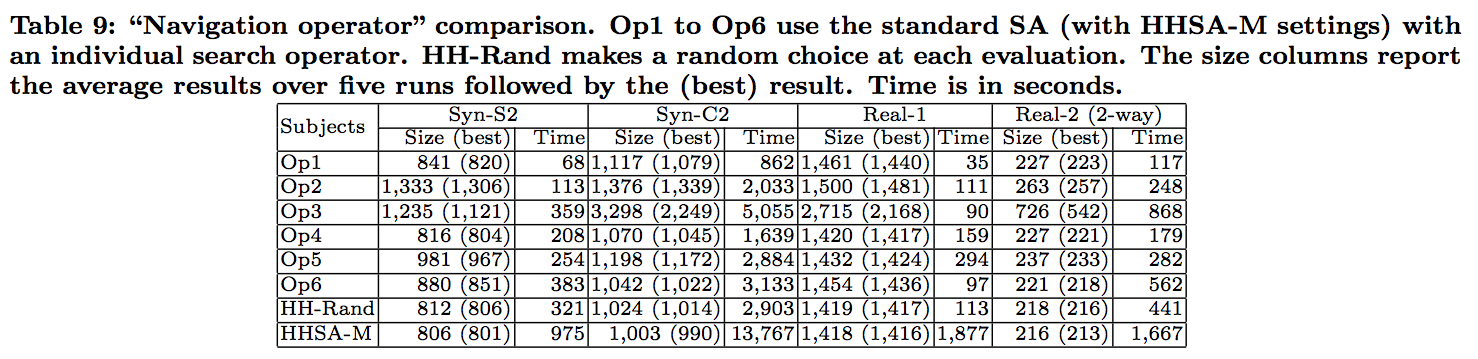
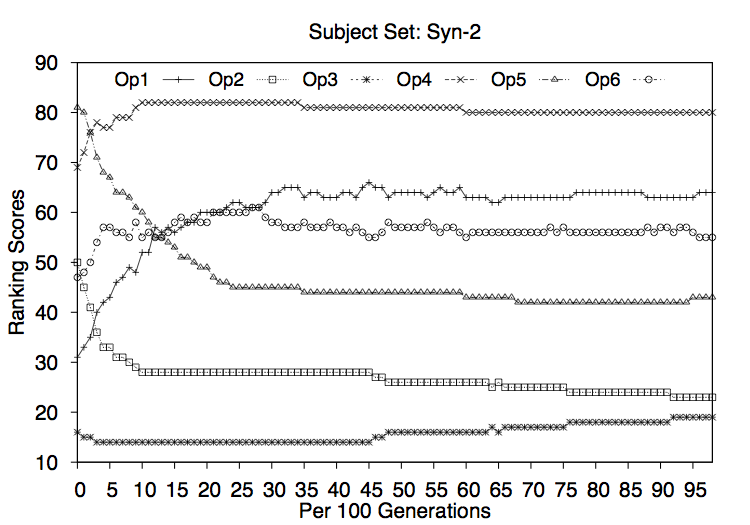
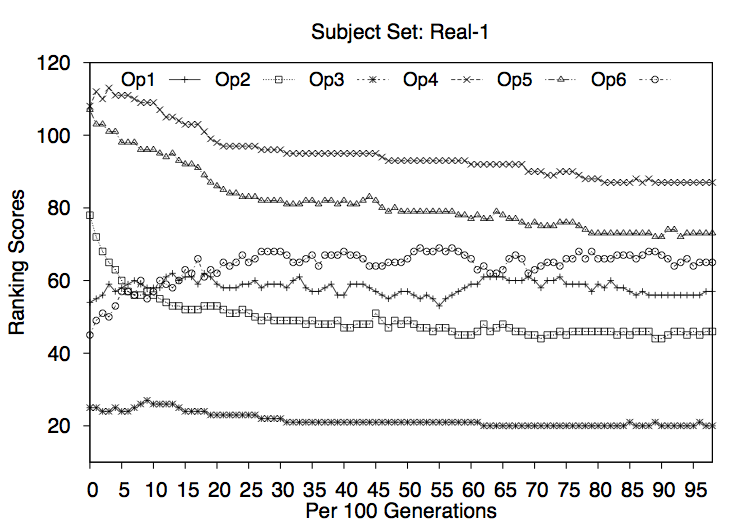
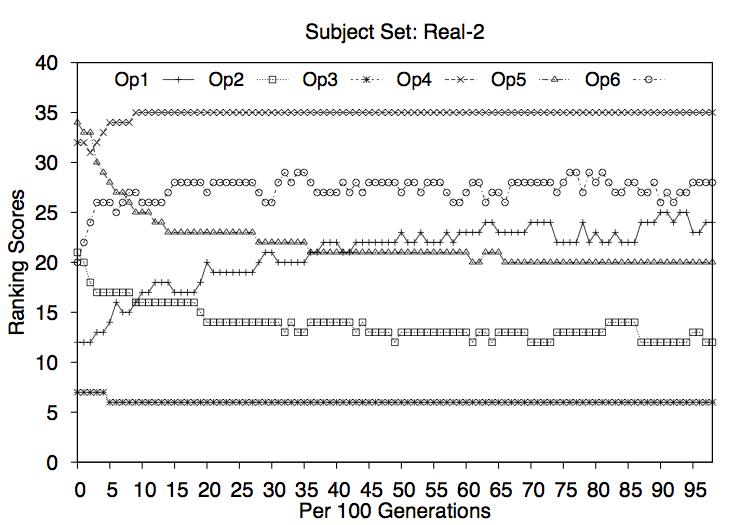
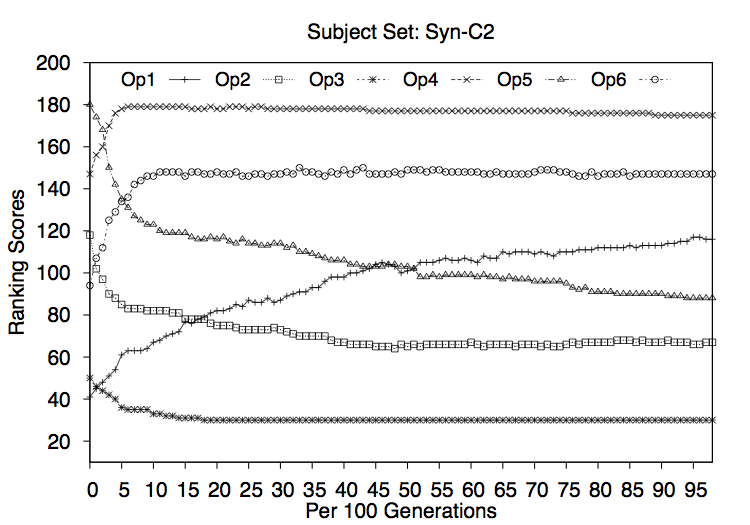
We conclude that there is a difference between effectiveness of each of the operators and that combining them contributes to a better quality solution
RQ4: Do we see evidence that the hyperheuristic approach is learning?
Should it turn out that the hyperheuristic approach performs well, finding competitively sized covering arrays in reasonable time, then we have evidence to suggest that the adaptive learning used by the hyperheuristic approach is able to learn which operator to deploy. However, is it really learning? This RQ investigates, in more detail, the nature of the learning taking place as the algorithm searches for interaction test suites. We explore how the problem difficulty varies over time for each of the CIT problems we study, and then ask which operators are chosen at each stage of difficulty; is there evidence that the algorithm is selecting different operators for different types of problems?
The following figures contain two examples showning the learning algoirhtm's reward scores for each operator over time.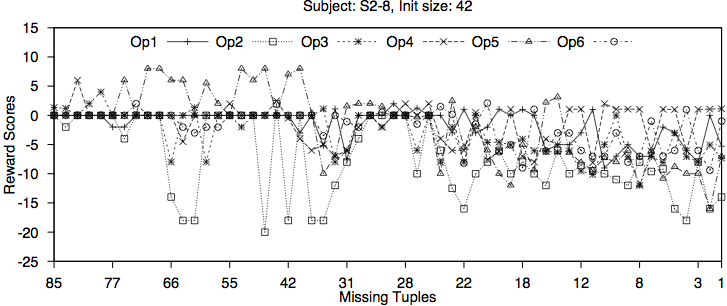
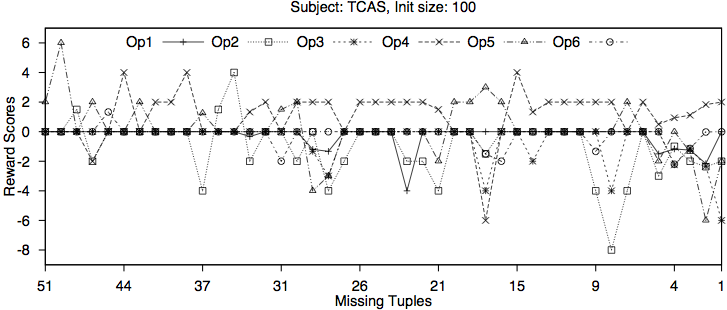
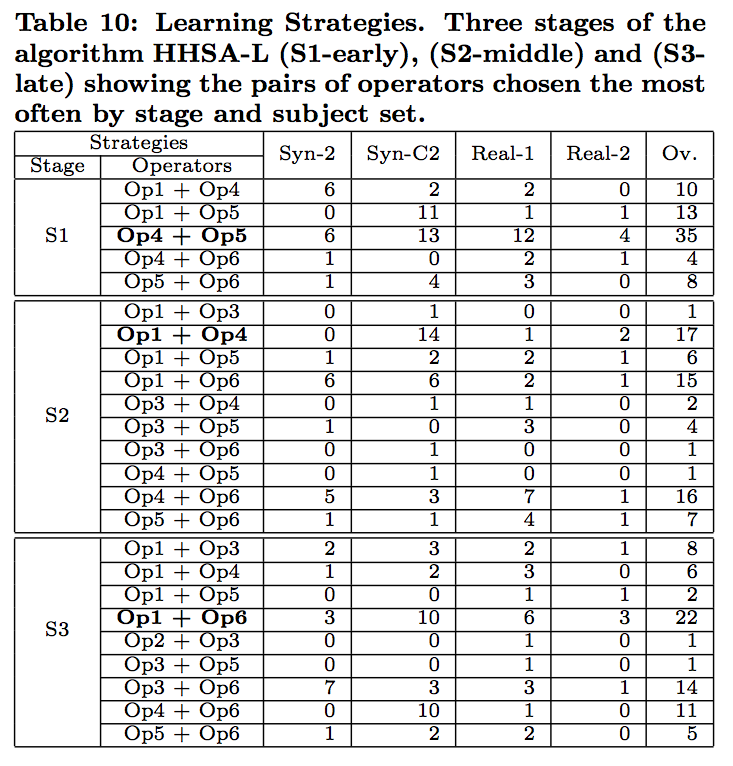
We see evidence that the Hyperheuristic algorithm is learning both at different stages of search and across different types of subjects.
Downloads
This download includes all the subjects we used in our study. Please note that the format of the constraint files used by HHSA is different from the format used by CASA. Download
Acknowledgments
The FITTEST project FP7/ICT/257574 supports Yue Jia. Mark Harman is supported by the EPSRC, EP/J017515/1 (DAASE), EP/I033688/1 (GISMO), EP/I010165/1 (RE-COST) and EP/G060525/2 (Platform Grant). RE-COST and DAASE also completely support Justyna Petke. Myra Cohen is supported in part by NSF award CCF-1161767.2012-2013 © Yue Jia, Myra Cohen, Mark Harman and Justyna Petke